How to use K-means to classify a histogram of a 1D data set using two features in time and value
井民全, Jing, mqjing@gmail.com
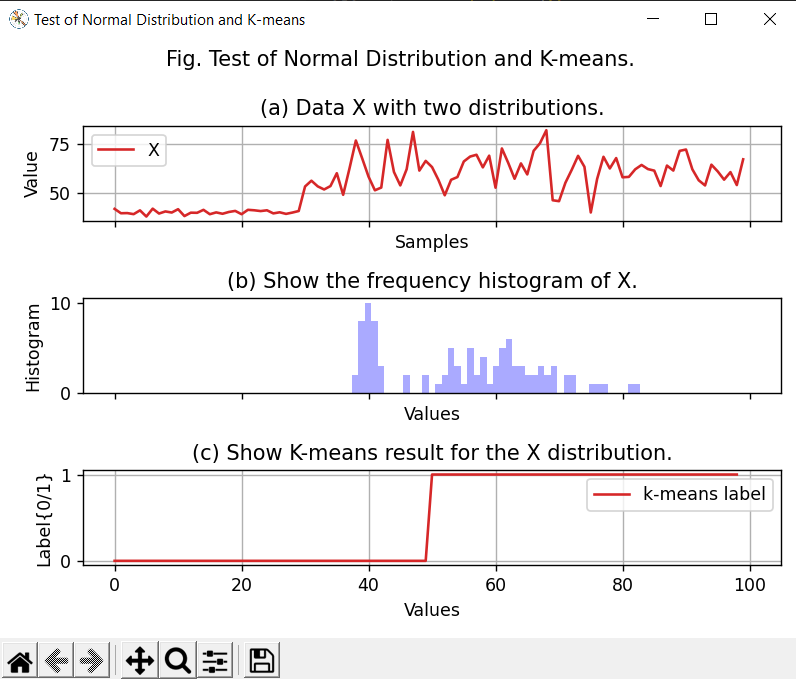
At first step, we crate a demo dataset by generating a 100 samples data array with mixed two distribution in which the first distribution has 30 samples with properties of means as 40 with standard deviation 1 and the second distribution has 70 samples with means as 60 and the standard deviation as 10. The second step, let k-means to classify the histogram of data and provide the cut result. |
Key points
(1) How to get the histogram bin for k-means
i = 1 bins = np.linspace(0, len(X), len(X)) axes[i].hist(X, bins=bins, fc='#AAAAFF') axes[i].set_title("(b) Show the frequency histogram of X.") axes[i].set_ylabel("Histogram") axes[i].set_xlabel("Values")
# get distributed bins p = axes[i].patches lstHistogram = [patch.get_height() for patch in p] |
(2) How to use k-means to classify the 1D data
# run k-means kmeans = KMeans(n_clusters=2) lstLabel = kmeans.fit_predict(list(zip([x for x in range(0, len(lstHistogram))], lstHistogram))) print(lstLabel) # get the k-means result lstIndex = np.where(np.abs(np.diff(lstLabel)) == 1)[0] print("The cut points, lstIndex = ", lstIndex) |
Code
np.random.seed(1) N = 100 # total samples # normal distribution list. mean = 40, std= 1, number of samples = 30% arrA = np.random.normal(40, 1, int(0.3 * N)) # normal distribution list. mean = 60, std= 10, number of samples = 70% arrB = np.random.normal(60, scale=10, size=int(0.7 * N)) X = np.concatenate((arrA, arrB))
fig, axes = plt.subplots(nrows=3, sharex=True, gridspec_kw={"height_ratios": [1,1,1]}) fig.suptitle('Fig. Test of Normal Distribution and K-means.') fig.canvas.set_window_title('Test of Normal Distribution and K-means')
# show all samples i = 0 axes[i].plot([x for x in range(0, X.size)], X, "tab:red", label="X") axes[i].set_title("(a) Data X with two distributions.") axes[i].set_ylabel("Value") axes[i].set_xlabel("Samples") axes[i].grid() axes[i].legend()
# show histogram i = 1 bins = np.linspace(0, N, N) axes[i].hist(X, bins=bins, fc='#AAAAFF') axes[i].set_title("(b) Show the frequency histogram of X.") axes[i].set_ylabel("Histogram") axes[i].set_xlabel("Values") # get distributed bins p = axes[i].patches lstHistogram = [patch.get_height() for patch in p] # run k-means kmeans = KMeans(n_clusters=2) lstLabel = kmeans.fit_predict(list(zip([x for x in range(0, len(lstHistogram))], lstHistogram))) print(lstLabel) lstIndex = np.where(np.abs(np.diff(lstLabel)) == 1)[0] print("The cut points, lstIndex = ", lstIndex) # show k-means result i = 2 axes[i].plot([x for x in range(0, len(lstLabel))], lstLabel, "tab:red", label="k-means label") axes[i].set_title("(c) Show K-means result for the X distribution.") axes[i].set_ylabel("Label{0/1}") axes[i].set_xlabel("Values") axes[i].grid() axes[i].legend()
plt.tight_layout() # Prvent the figure title overlaps axes label plt.show() |
Result
Figure
Stdout
fig.canvas.set_window_title('Test of Normal Distribution and K-means') [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1] The cut points, lstIndex = [49] |
References
https://numpy.org/doc/stable/reference/random/generated/numpy.random.normal.html
https://numpy.org/doc/stable/reference/generated/numpy.where.html
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html